
源码:awesome-nest
在 nestjs入门(一) 中,对 Nestjs 一些重要的概念有了一些了解,现在我们开始创建一个基于 Nestjs 的应用吧。
Nestjs 和 Angular 一样,提供了 CLI 工具帮助我们初始化和开发应用程序。
1 | $ npm install -g @nestjs/cli |
这时候你会得到这样的一个目录结构:
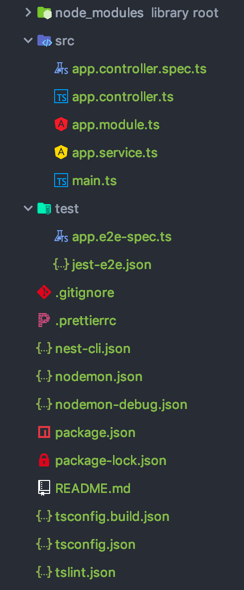
运行npm start后,在浏览器访问http://localhost:3000/就可以看到Hello World!。
Controller 和 Service
在 Nestjs 中,所有的 controller 和 service 都要在对应的 module 中注册,就像这样:
1 | import { Module } from '@nestjs/common'; |
在 MVC 模式中,controller 通过 model 获取数据。对应的,在 Nestjs 中,controller 负责处理传入的请求, 并调用对应的 service 完成业务处理,返回对客户端的响应。
通常可以通过 CLI 命令来创建一个 controller:
1 | $ nest g co cats |
这时候,CLI 会自动生成 controller 文件,并且把 controller 注册到对应的 module 中。
和其他一些 node 框架不一样,Nestjs 路由不是集中式管理,而是分散在 controller 中,通过@controller()中声明的(可选)前缀和请求装饰器中指定的任何路由来确定的。
1 | import { Controller, Get } from '@nestjs/common'; |
上面这段代码中,通过 Get 请求去请求http://localhost:3000/cats/1就会调用findOne方法。
如果需要在所有请求之前加上 prefix,可以在main.ts中直接设置 GlobalPrefix:
1 | import { NestFactory } from '@nestjs/core'; |
在 Nestjs 中,controller 就像是调用 service 的指挥者,把对应的请求分发到相应的 service 中去处理。
在 controller 中,我们注意到,在构造函数中注入了CatsService实例,来调用对应 service 中的方法。这就是 Nestjs 中依赖注入的注入方式 — 构造函数注入。
service 可以看做夹在 controller 和 model 之间的一层,在 service 调用 DAO (在 Nestjs 中是各种 ORM 工具或者自己封装的 DAO 层)实现数据库的访问,进行数据的处理整合。
1 | import { Injectable } from '@nestjs/common'; |
上面代码中通过@Injectable()定义了一个 service,这样你就可以在其他 controller 或者 service 中注入这个 service。
DTO 和 Pipe
通过nestjs入门(一)已经介绍了 DTO 的概念,在Nestjs 中,DTO 主要定义如何通过网络发送数据的对象,通常会配合class-validator和class-transformer做校验。
1 | import { IsString, IsInt } from 'class-validator'; |
1 | import { Controller, Get, Query, Post, Body, Put, Param, Delete } from '@nestjs/common'; |
上面对请求body 定义了一个 DTO,并且在 DTO 中对参数类型进行了限制,如果body中传过来的类型不符合要求,会直接报错。
DTO 中的class-validator 还需要配合 pipe 才能完成校验功能:
1 | import { |
这个 pipe 会根据元数据和对象实例,去构建原有类型,然后通过validate去校验。
这个 pipe 一般会作为全局的 pipe 去使用:
1 | async function bootstrap() { |
假设我们没有这层 pipe,那在 controller 中就会进行参数校验,这样就会打破单一职责的原则。有了这一层 pipe 帮助我们校验参数,有效地降低了类的复杂度,提高了可读性和可维护性。
Interceptor 和 Exception Filter
代码写到这里,我们发现直接返回了字符串,这样有点太粗暴,需要把正确和错误的响应包装一下。假设我希望返回的格式是这样的:
1 | # 请求成功 |
此时,可以利用 AOP 的思想去做这件事。首先,我们需要全局捕获错误的切片层去处理所有的 exception;其次,如果是一个成功的请求,需要把这个返回结果通过一个切片层包装一下。
在 Nestjs 中,返回请求结果时,Interceptor 会在 Exception Filter 之前触发,所以 Exception Filter 会是最后捕获 exception的机会。我们把它作为处理全局错误的切片层。
1 | import { |
而 Interceptor 则负责对成功请求结果进行包装:
1 | import { |
同样 Interceptor 和 Exception Filter 需要把它定义在全局范围内:
1 | async function bootstrap() { |
TypeORM
TypeORM 相当于 Nestjs 中的 DAO 层,它支持多种数据库,如 PostgreSQL,SQLite 甚至MongoDB(NoSQL)。这里我们以 MySQL 为例,首先在 MySQL 中手动创建一个数据库:
1 | > CREATE DATABASE test |
然后安装 typeorm:
1 | $ npm install --save @nestjs/typeorm typeorm mysql |
通常我们开发的时候,会有多套环境,这些环境中会有不同的数据库配置,所以先建一个config文件夹,放置不同的数据库配置:
1 | // index.ts |
1 | // prod.config.ts |
在线上环境强烈不建议开启 orm 的 synchronize功能。本地如果要开启,要注意一点,如果 entity 中定义的字段类型和数据库原有类型不一样,在开启synchronize 后 orm 会执行 drop然后再add的操作,这会导致本地测试的时候数据丢失(这里为了方便,本地测试就把synchronize功能打开,这样写完 entity 就会自动同步到数据库)。
在app.module.ts中导入TypeOrmModule:
1 | import { Module } from '@nestjs/common' |
接下来就是写 entity,下面我们定义了一个叫cat的表,id为自增主键:
1 | import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm' |
这时候,entity 就会同步到数据库,在test数据库中,就能看到cat这张表了。
在某个模块使用这个 entity 的时候,需要在对应的模块中注册,使用 forFeature() 方法定义定义哪些存储库应在当前范围内注册:
1 | import { Module } from '@nestjs/common' |
这时候就可以用@InjectRepository() 修饰器向 CatService 注入 CatRepository:
1 | import { Injectable } from '@nestjs/common' |
这时候去请求http://localhost:3000/api/v1/cats/1这个 API,就会返回下面结果:
1 | { |
在 typeorm 中,如果需要用到比较复杂的 sql 语句,可以使用 createQueryBuilder帮助你构建:
1 | this.catRepository |
如果 createQueryBuilder不能满足你的要求,可以直接使用query写 sql 语句:
1 | this.catRepository.query( |
Migration
在持续交付项目中,项目会不断迭代上线,这时候就会出现数据库改动的问题,对一个投入使用的系统,通常会使用 migration 帮我们同步数据库。TypeORM 也自带了一个 CLI 工具帮助我们进行数据库的同步。
首先在本地创建一个ormconfig.json文件:
1 | { |
这个 json 文件中指定了 entity 和 migration 文件的匹配规则,并且在 CLI 中配置了 migration 文件放置的位置。
这时候运行下面命令就会在 migrations 文件夹下面自动生成1563725408398-update-cat.ts文件
1 | $ ts-node node_modules/.bin/typeorm migration:create -n update-cat |
文件名中1563725408398是生成文件的时间戳。这个文件中会有up和down这两个方法:
1 | import {MigrationInterface, QueryRunner} from "typeorm"; |
up必须包含执行 migration 所需的代码。 down必须恢复任何up改变。在up和down里面有一个QueryRunner对象。 使用此对象执行所有数据库操作。比如我们在 cat 这张表中写入一个假数据:
1 | import {MigrationInterface, QueryRunner} from "typeorm"; |
这时候,在 package.json中写入下面 script 并运行npm run migration:run,这时候 cat 表里面就会有一个id为2的假数据。
1 | { |
注意,这个ormconfig.json文件的配置是本地环境的配置,如果需要在生成环境使用,可以重新写一份ormconfig-prod.json,然后运行migration命名的时候加上--config ormconfig-prod.json。
用 typeorm 生成的 migration 有一个缺点,sql 和代码都耦合在一起,最好还是 sql 是单独一个文件,migration 脚本是一个文件,这样如果特殊情况下,方便直接在 MySQL 中运行这些 sql 文件。这时候,可以用db-migrate来代替 typeorm 来管理 migration 脚本,db-migrate 会在 migration 目录下面生成一个 js 脚本和两个 sql 文件,这两个 sql 文件一个是up的 sql,一个是down的 sql。
对于已有项目,如果根据数据库从头开始创建对应的 entity 是一件很麻烦的事情,这时候,可以使用typeorm-model-generator来自动生成这些 entity 。比如运行下面命令:
1 | $ typeorm-model-generator -h 127.0.0.1 -d arya -p 3310 -u root -x 123456 -e mysql -d test -o 'src/entities/' --noConfig true --cf param --ce pascal |
这时候就会在src/entities/下面生成cat.ts的 entity 文件:
1 | import {BaseEntity,Column,Entity,Index,JoinColumn,JoinTable,ManyToMany,ManyToOne,OneToMany,OneToOne,PrimaryColumn,PrimaryGeneratedColumn,RelationId} from "typeorm"; |
日志
官方给出了日志的解决方案,不过这里我们参照nestify,使用log4js做日志处理。主要原因是 log4js 对日志进行了分级、分盘和落盘,方便我们更好地管理日志。
在 log4js 中日志分为九个等级:
1 | export enum LoggerLevel { |
ALL和OFF 这两个等级一般不会直接在业务代码中使用。剩下的七个即分别对应 Logger 实例的七个方法,也就是说,在调用这些方法的时候,就相当于为这些日志定了级。
对于不同的日志级别,在 log4js 中通过不同颜色输出,并且输出时候带上日志输出时间和对应的 module name:
1 | Log4js.addLayout('Awesome-nest', (logConfig: any) => { |
在 log4js 中,日志的出口问题(即日志输出到哪里)由 Appender 来解决:
1 | Log4js.configure({ |
config 中配置了debug级别以上的日志会通过console输出。
接下来就是export一个 log class,对外暴露出 log4js 中不同等级的 log 方法以供调用,完整代码如下:
1 | import * as _ from 'lodash' |
这样在需要输出日志的地方只要这样调用就行:
1 | Logger.info(id) |
可是我们并不希望每个请求都自己打 log,这时候可以把这个 log 作为中间件:
1 | import { Logger } from '../../shared/utils/logger' |
在main.ts中注册:
1 | async function bootstrap() { |
并且在ExceptionsFilter中也对捕捉到的 Exception 进行日志输出:
1 | export class ExceptionsFilter implements ExceptionFilter { |
这样一个基础的日志输出系统差不多就完成了。当然,log4js 的appender还支持下面几种:
DateFile:日志输出到文件,日志文件可以安特定的日期模式滚动,例如今天输出到
default-2016-08-21.log,明天输出到default-2016-08-22.log;SMTP:输出日志到邮件;
Mailgun:通过 Mailgun API 输出日志到 Mailgun;
levelFilter 可以通过 level 过滤;
等等其他一些 appender,到这里可以看到全部的列表。
比如,下面配置就会把日志输出到加上日期后缀的文件中,并且保留 60 天:
1 | Log4js.configure({ |
CRUD
对于一般的 CRUD 的操作,在 Nestjs 中可以使用@nestjsx/crud这个库来帮我们减少开发量。
首先安装相关依赖:
1 | npm i @nestjsx/crud @nestjsx/crud-typeorm class-transformer class-validator --save |
然后新建dog.entity.ts:
1 | import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm' |
在dog.service.ts中只需写下面几行代码:
1 | import { Injectable } from '@nestjs/common' |
在dog.controller.ts中,使用@crud帮助自动生成API:
1 | import { Controller } from '@nestjs/common' |
这时候,就可以按照@nestjsx/crud的文档中 API 规则去请求对应的 CRUD 的操作。比如,请求GET api/v1/dogs,就会返回所有 dog 的数组;请求GET api/v1/dogs/1,就会返回 id为1的 dog。


